Title here
Summary here
2024/01-04/2024 Python BERT Recommendation Systems ReactJS Flask
This was a project that I worked on in the class Data and Visual Analytics (CSE-6242) at Georgia Tech’s OMSA program, parterned with teamates Ryan Tsedevsuren, Tyler David, Terrance Patric Lenaghan, Timothy Zhang, Swathi Naik.
We wanted to create a book webapp that allows interactive query and recommendation visualizations, built on top of the datasets goodbooks-10k and Project Gutenberg.
We want to implement both the CF (collaborative filtering) and CBF (content-based filtering) functionalities; an brief overview of what these do can be found in this Wikipedia link, or this textbook1. We intended the user to interact with the app in the following ways:
bert-base-uncased model.surprise library. However we found that some sparse implementations and fine-tweaks might be needed to fit our needs, so I decided to implment it myself.flask.material-ui, react-force-graph React libraries.To appear: System Design Diagram
My contributions are summarized in the following table:
| Components | Implementation | Role |
|---|---|---|
| Frontend - UI | material-ui | Main implementation |
| Frontend - Visualization | react-force-graph | Main implementation |
| Backend | flask | Exposed CF Functionality as an API endpoint |
| Modeling - CF | From scratch | Implemented CF from scratch, and tested different similarity metrics via 9-fold CV |
The final app has the following look (animated GIF generated from our unlisted YouTube Video Demo, produced with CLI tools yt-dlp, ffmpeg, magick):
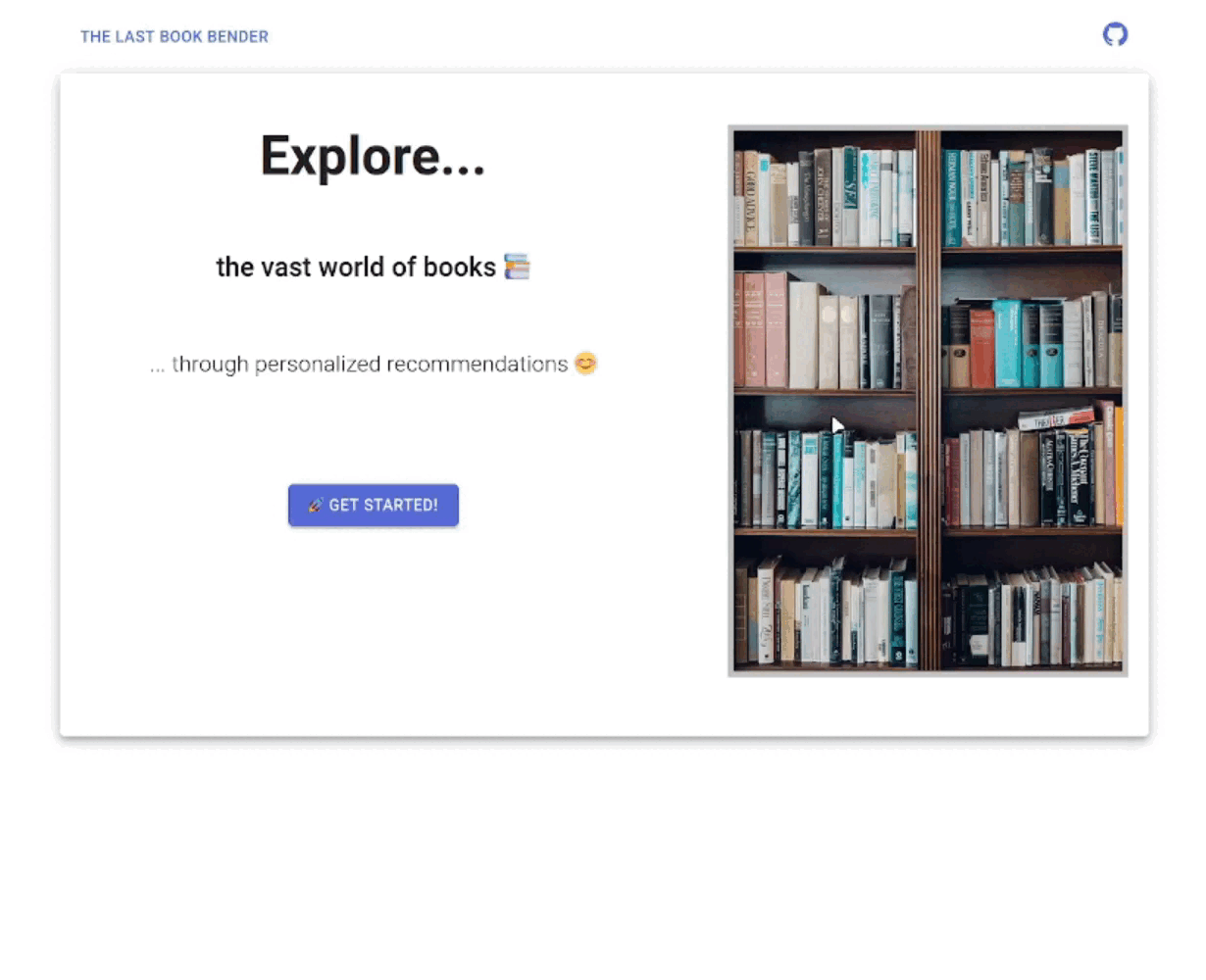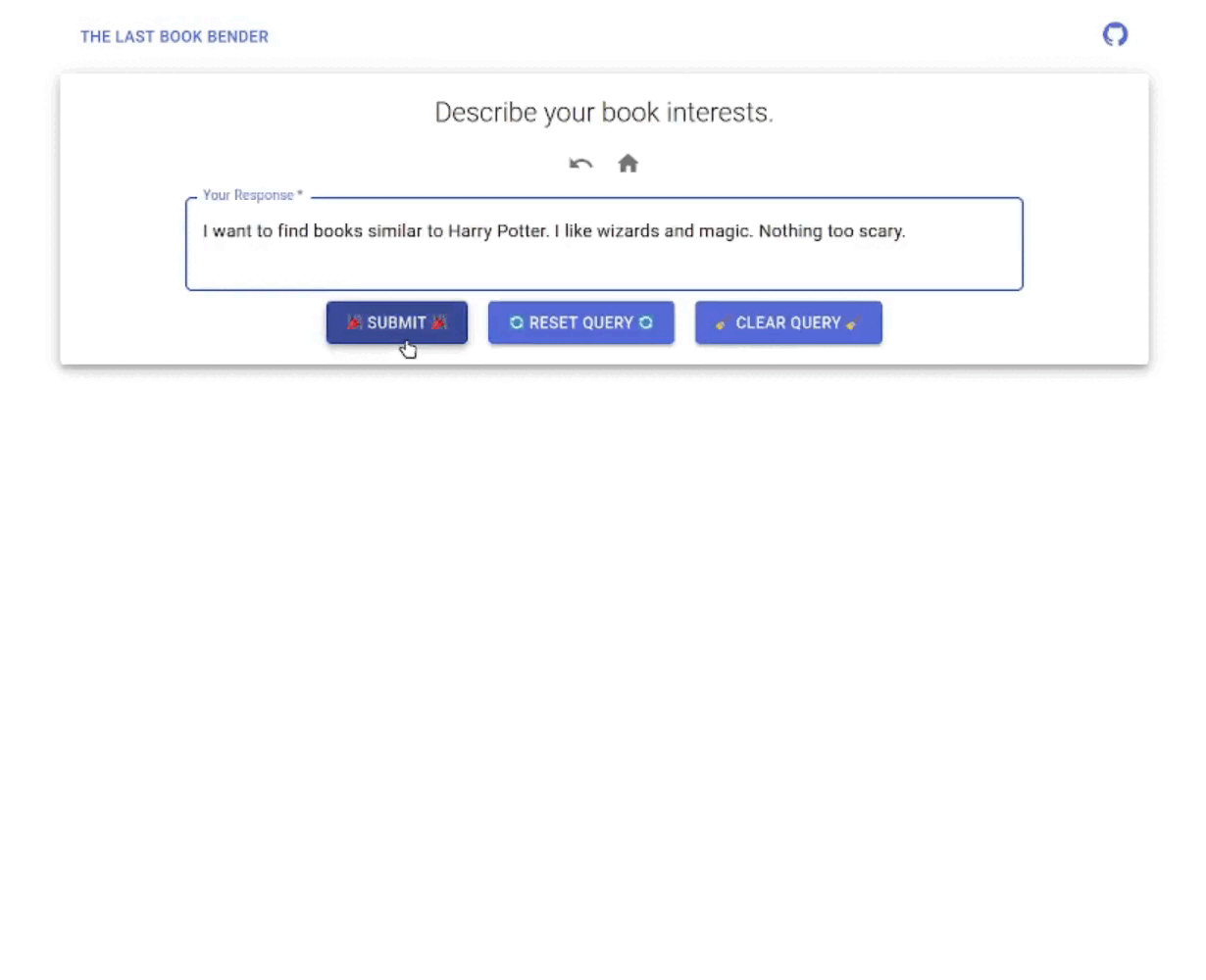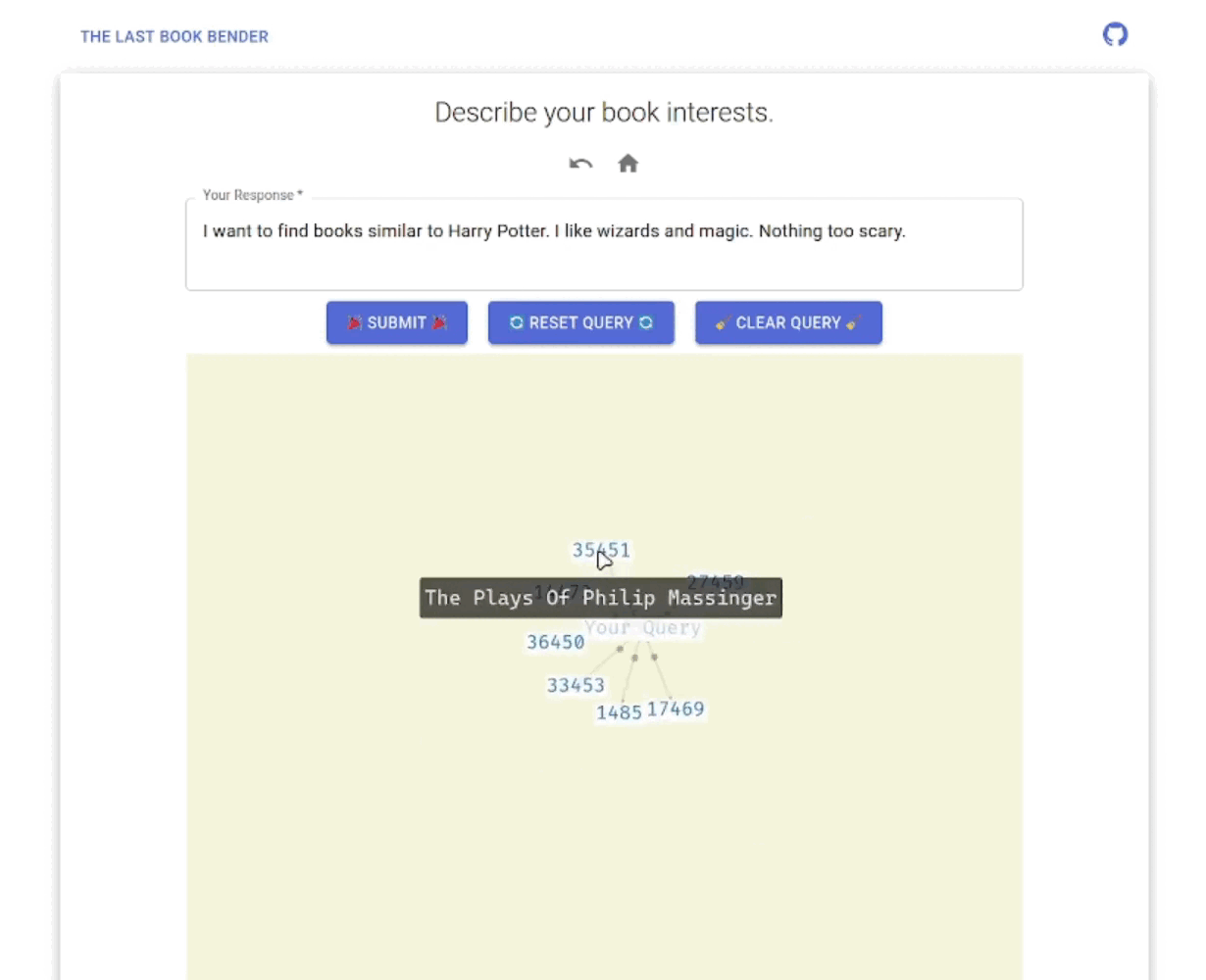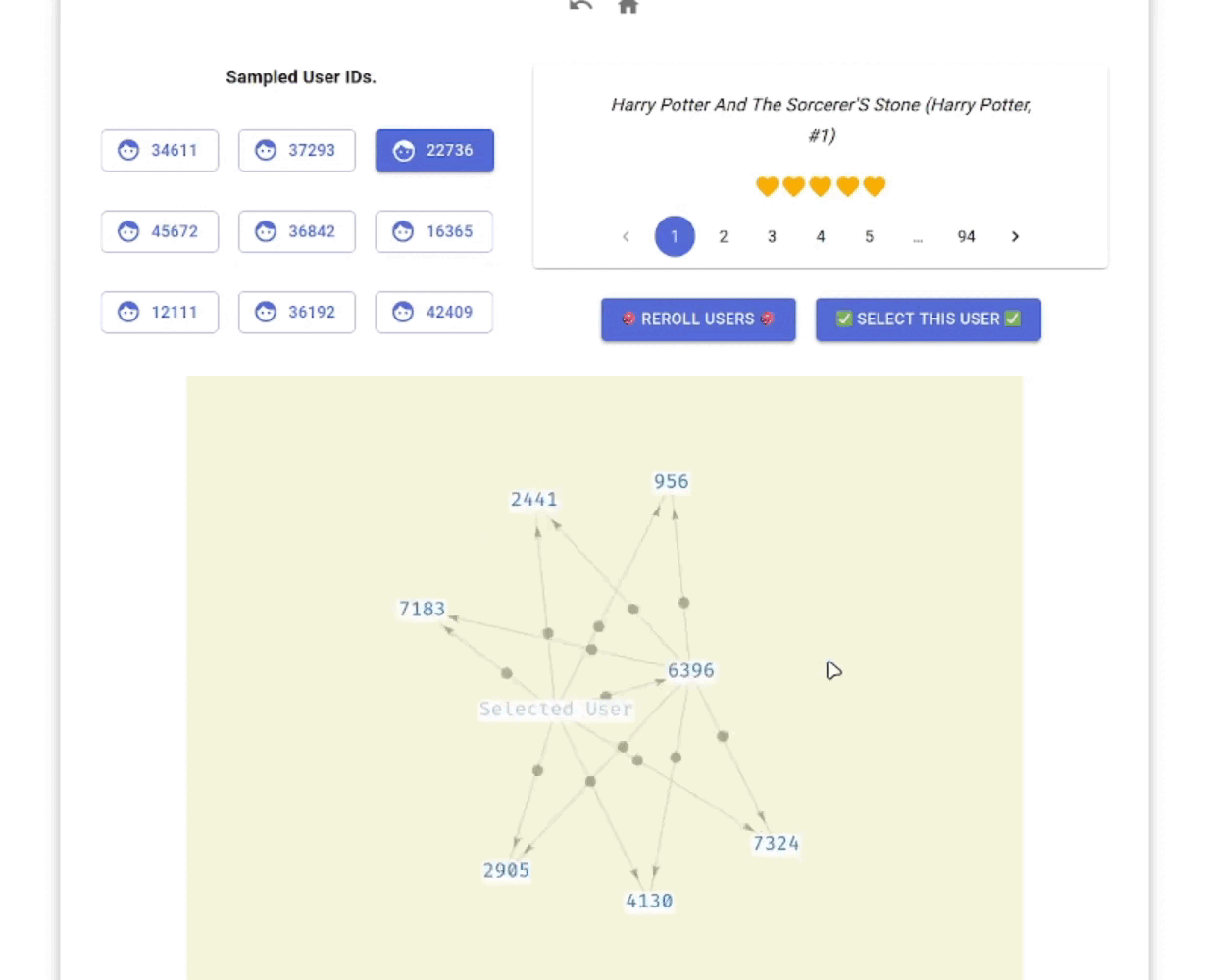
I thought the idea of project was pretty cool, but I will talk about some improvement directions and related takeaways on my side (some of which are things that I wished I had more time to spent working on on my part):
Deployment Issues: We tried to find free solutions for deploying this webapp online, but the final webapp was pretty large, so we decided to keep it as an app that can be built locally. The main reason was that the backend functionality for CBF uses the entire bert-base-uncased model, which was about 0.5GB in size (without accounting for the size of other Python libraries needed). A possible direction for improvement is to use distilled version of it (either distilbert-base-uncased or TinyBERT_General_4L_312D).
Exploration Issues: The exploration ability of the force graph is actually pretty limited - each time we generate top 5 recommendations, but we often ended up in a complete graph, and each node expands to nodes that we have seen before, making the exploration process stagnant. We do not know if this is an issue in our modeling process (whether the CBF or the CF part), our data (where we have very strong nodes dominating the whole graph).
UI/UX Issues: The view for existing users is extremely inconvenient - I implemented in a way that one can only click alone one direction to look at one book at a time. This is one part that I wanted to improve, but I was not very adept with the MUI library at that time.
RWD Design: I didn’t have time finishing the webapp design for adaptability for devices of various size, which is a crucial aspect of modern webapp development, although breakpoints for media queries were used.
I learned a lot from this project:
Most importantly, this is my first time trying to build an end-to-end pseudo-complete data product with a team. It might be a weird to say this, but I always find it exciting and happy to see when datas “doing things”.
Aggarwal, Charu C. Recommender systems. Vol. 1. Cham: Springer International Publishing, 2016. ↩︎