Title here
Summary here
2024/01-04/2024 Python Recommendation systems LaTeX
This was a project that I worked on in the class Computational Data Analytics (ISYE-6740) at Georgia Tech’s OMSA program, parterned with teamates Garrison Winters, Molly M. Bartley.
The following is a screenshot of the report, illustrating the key ideas.
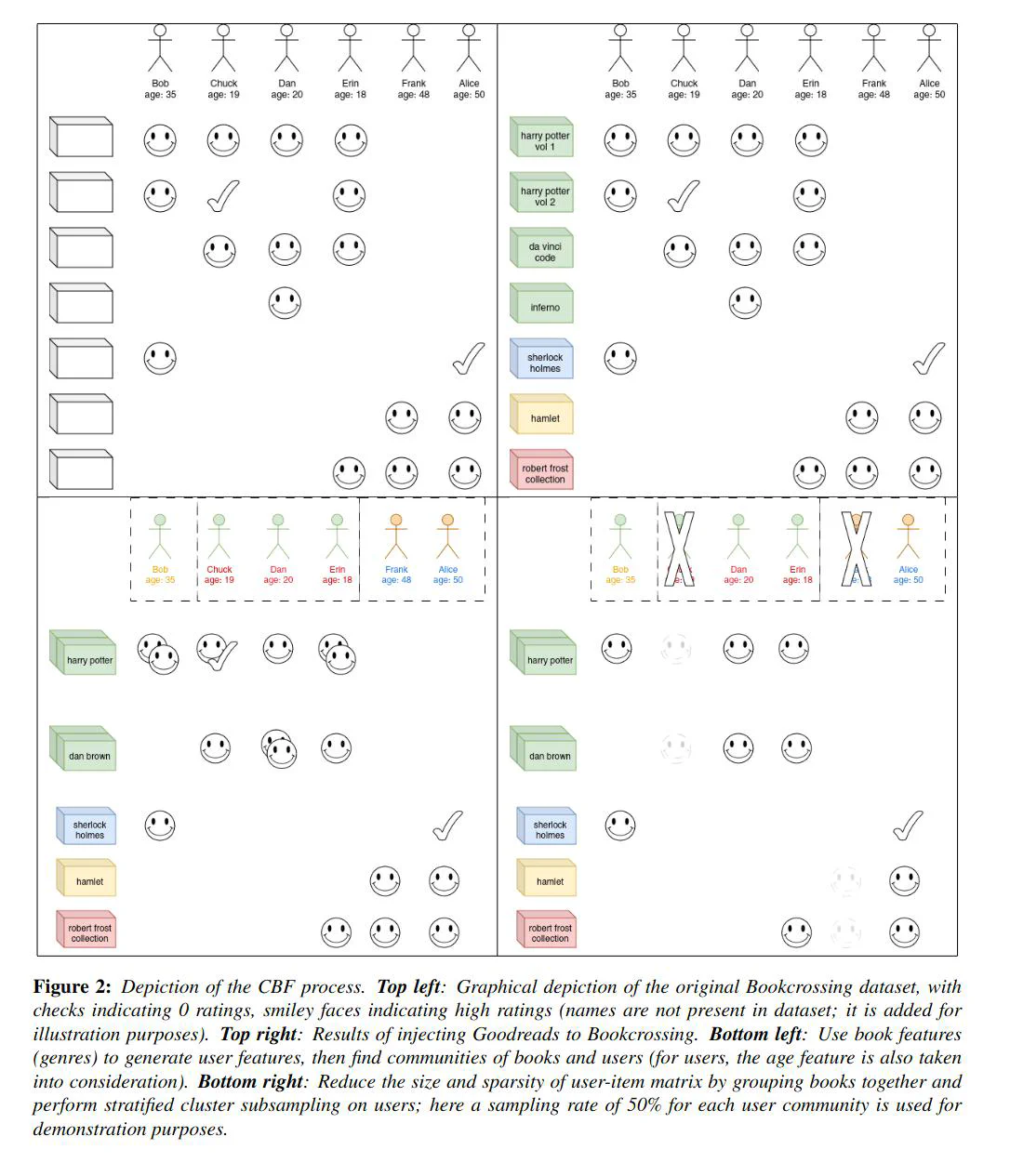
We wanted to use the basic collaborative filtering (CF) algorithm to build a book recommender system, from the famous BookCrossing Dataset originally collected by Cai-Nicolas Ziegler, and evaluate performance via n-fold cross-validated MAE, MSE.
The problem is that the size of the dataset as well as the sparsity of the user-item matrix makes direct application of the CF algorithm to this dataset a less ideal choice. This project is an exploration of ways to scale CF to BookCrossing.
Our idea is a type of dimensionality reduction technique, using content-based filtering (CBF), with external data injected into BookCrossing. We did the following to get a reduced user-item matrix:
tfidfvectorizer)NearestNeighbors)louvain_communities) to generated book clusters.The before-and-after after this reduction is given in the following table:
| #U | #I | #R | #R/#U#I | |
|---|---|---|---|---|
| B | 7.69e+4 | 1.09e+5 | 7.35e+5 | 8.79e-5 |
| A | 6.84e+3 | 6.58e+3 | 8.83e+4 | 1.96e-3 |
| A/B | 8.89e-2 | 6.05e-2 | 1.20e-1 | 2.23e+1 |
(A: After, B: Before, U: Users, I: Items, R: Ratings)
My contributions are summarized in the following table:
| Components | Role |
|---|---|
| Modeling | Formulated main idea, coded CF algorithm |
| Data Preparation | Communicated what is needed for modeling |
| EDA | None |
| Validation | Implemented 10-fold CV |
| Reporting | Combined and typesetted teammates inputs into a
 report
report |
We were able to reach a best 10-fold cross-validated MAE/RMSE around 0.95, 1.37 (where the ratings are on a scale from 1 to 10), but with reduced memory usage and increasd speed in terms of predictions. Details are given in our report.
Although CF, CBF are some of the most basic recommender algorithms, I am still pretty happy about this project 🤗 - it has some little quirky uncommon data modeling ideas, and worked pretty fine!